③金額集計(確定損益・スワップ)groupby/sum
集計(計算)するためにはいくつか準備が必要となります。
準備としては
・dfのデータ型を調べる
・「,」を取り除く
・dfのデータ型を変える
・集計をする
の順番で行います。
順番
dfのデータ型を調べる
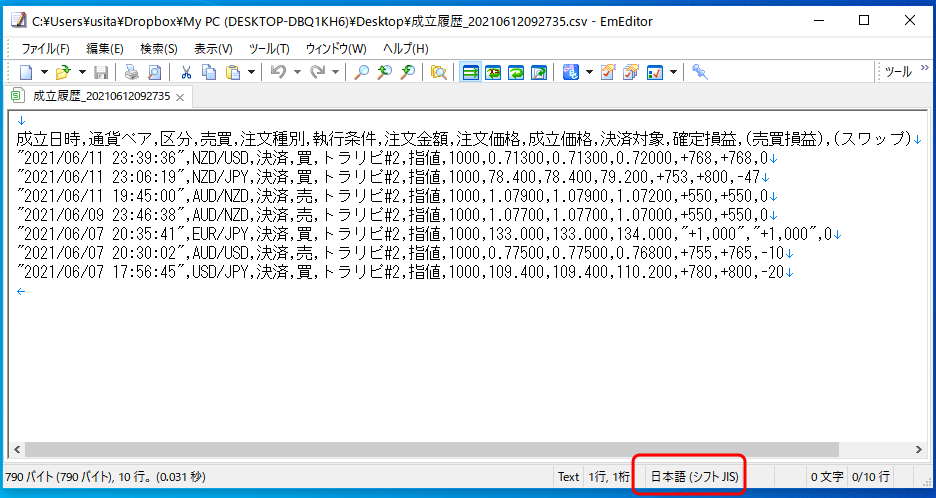
dfのデータ
通貨ペア 確定損益 (スワップ) 2 AUD/JPY +673 -227.0 4 EUR/JPY +1,000 0.0 6 NZD/JPY +625 -175.0 7 NZD/USD +771 0.0
「確定損益」と「スワップ」の合計を計算するためには、
dfのデータが数字型でないと計算できません。
そこでまずdfのデータ型を調べます。
#dfのデータ型を調べる print(df.dtypes)
上記のように入力すると、
通貨ペア object 確定損益 object (スワップ) float64 dtype: object
と結果表示されます。
スワップは「float64」で数字型ですからそのまま計算できます。
しかし、確定損益は「object」のため文字扱いされて計算でません。
dfのデータ
通貨ペア 確定損益 (スワップ) 2 AUD/JPY +673 -227.0 4 EUR/JPY +1,000 0.0 6 NZD/JPY +625 -175.0 7 NZD/USD +771 0.0
↑こんな感じで4の「EUR/JPY」の確定損益には「,」が付いており、
このままですと数字として認識されません。
そこで
・「,」を取り除く
・データ型を「int」(数字型)に変換
という作業を行います。
・「,」を取り除く
#+1,000を+1000に置き換える
if df['確定損益'].dtype == object:
df['確定損益'] = df['確定損益'].str.replace(',', '')
・データ型を「int」に変換
df = df.astype({'確定損益': int})
df['確定損益'] = df['確定損益'].str.replace(',', '')
dfの項目「確定損益」の文字列データの「,」(',')を、
「,がない状態」(’’)にreplaceを使って置き換える。
その結果
置換後のdf--------------------------------------------------- 通貨ペア 確定損益 (スワップ) 2 AUD/JPY +673 -227.0 4 EUR/JPY +1000 0.0 6 NZD/JPY +625 -175.0
でも、なぜ「if」文なのか?
表示されるデータですが今回は「1,000」が含まれていました。
しかし「1,000」が含まれていない時もあります。
例えば、
通貨ペア 確定損益 (スワップ) 0 NZD/USD 763 0 1 NZD/JPY 771 -29 2 AUD/JPY 873 -27 3 NZD/JPY 792 -8 4 CAD/JPY 801 1 5 AUD/USD 748 -15
上記のような場合データ型を調べてみると、
通貨ペア object 確定損益 int64 (スワップ) int64 dtype: object
となり「通貨ペア」「スワップ」どちらとも「int64」で数字型です。
だからそのまま計算できます。
その場合、df['確定損益'] = df['確定損益'].str.replace(',', '')
だけのコードですと、「,」がないためエラー表示されます。
ですからobjectがある場合とない場合を
if文で振り分ける必要がでてきます。
・集計をする
変換できたら集計します。
dfのデータ
通貨ペア 確定損益 (スワップ) 2 AUD/JPY +673 -227.0 4 EUR/JPY +1000 0.0 6 NZD/JPY +625 -175.0 7 NZD/USD +771 0.0 9 AUD/JPY +678 -222.0 12 NZD/JPY +635 -165.0 13 EUR/JPY +1000 0.0 16 AUD/JPY +753 -147.0 17 EUR/JPY +1000 0.0 19 NZD/USD +773 0.0 20 NZD/JPY +679 -121.0 21 AUD/JPY +775 -125.0 25 EUR/JPY +1000 0.0 26 EUR/JPY +1000 0.0 27 EUR/GBP +1135 52.0 28 NZD/USD +774 0.0 30 NZD/JPY +742 -58.0 32 NZD/USD +771 0.0
上記のdfデータを見ると通貨ペアの重複があります。
例えば「EUR/JPY」ですと5回ほどでてきます。
そこで「groupby」で通貨ペアをまとめ
「確定損益」「スワップ」項目での合計を集計するコードを書きます。
#通貨ペアごとの損益/(スワップ)集計
df_tuka = df.groupby('通貨ペア').sum()[['確定損益','(スワップ)']]
df.groupby('通貨ペア').sum()[['確定損益','(スワップ)']]
通貨ペアでまとめ(groupby).確定損益/スワップの合計(sum)と書きます。
dfデータをdf_tukaデータとして表示します。
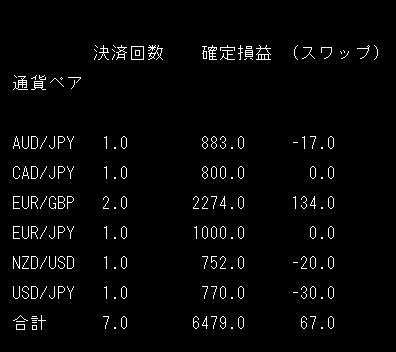
結果df_tukaデータ
確定損益 (スワップ) 通貨ペア AUD/JPY 2879 -721.0 EUR/GBP 1135 52.0 EUR/JPY 5000 0.0 NZD/JPY 2681 -519.0 NZD/USD 3089 0.0
となります。